从高等数学和线性代数的角度认识神经网络模型
更新: Invalid Date 字数: 0 字 时长: 0 分钟
本文将使用大学理工科均会学习的《高等数学》和《线性代数》的内容来由浅入深地讲解深度学习中最基础最重要的MLP多层感知机模型。
MLP 是深度学习中最基本的模型架构之一。它由多个神经元层组成,相邻层之间的神经元通过权重连接,信息从输入层经过隐藏层传递到输出层,每一层的神经元对输入进行加权求和并通过激活函数进行非线性变换。这种架构为理解和构建更复杂的深度学习模型提供了基础,许多其他深度学习模型,如卷积神经网络(CNN)、循环神经网络(RNN)及其变体(如 LSTM、GRU)等,都是在 MLP 的基础上进行改进和扩展而来的。
为了防止读者在阅读时出现读着读着看不懂的情况,在讲解之前我将列出必要的前置知识和一些专有名词的解释:
- 至少熟悉《高等数学》中的基本求导法则、链式求导方法以及梯度的概念
- 至少熟悉《线性代数》中矩阵乘法,行列式的计算
- 字段、特征、变量:在一个数据表格中,列就是字段,列名就是字段名,在机器学习领域中字段也被称为特征或者变量
- 目标、标签、label:在一个数据表格中,分类任务或者回归任务所指定的字段就是“目标、标签、label”,例如对于“根据温度、湿度、风向预测是否降雨”就是一个分类任务,其label就是“是否降雨”
- 机器学习:使用标记数据进行训练,即数据集中既有输入特征,也有对应的输出标签(目标值)。模型通过学习输入特征与输出标签之间的映射关系,来对新的未知数据进行预测。数据通常为表格形式
- 深度学习:是机器学习的一个分支领域,它是一种基于对数据进行表征学习的方法
- 线性关系:对于任意个数的变量,描述变量与目标的式子中只有一次项,可视为线性关系,如y=kx+b,固定宽度下矩形面积和矩形长度的关系
- 非线性关系:变量之间不存在线性关系,不能用线性方程来描述的关系称为非线性关系,例如“根据温度、湿度、风向预测是否降雨”这个问题中温度、湿度、风向、是否降雨这几个变量的关系是非线性的
在神经网络模型爆火的这几年,你可能已经看到过或者不止一次看到过如上图这样的“圆点之间以线相连”的结构图,这是MLP神经网络模型的结构示意图,实际上MLP神经网络不是这样的一个形状,但是我们可以通过这个形状去了解神经网络以下,我将首先介绍MLP神经网络的运行过程,再讲解MLP神经我们的组成,最后再讲解神经网络的学习原理
MLP神经网络处理任务时的运行过程
我们还是以前面提到“根据温度、温度、风向预测是否降雨”这个分类问题为例,这个问题中特征指的就是“温度,温度,风向”,label指的就是“是否降雨”,在这个问题中可能会提供的数据是一个表格,表格内记录着的内容可能是“温度,温度,风向,是否降雨”这几个字段的观测值,例如其中一行数据可能是“温度:37,湿度:55,风向:东南风,是否降雨:是”,表格内的数据是既有特征也有label的,而且这个表格应该是基于现实情况观测得来的而不是随意地拼接几个字段信息得来,这个表格就是给到模型的训练数据。面对这个问题,我们可能如下的模型,
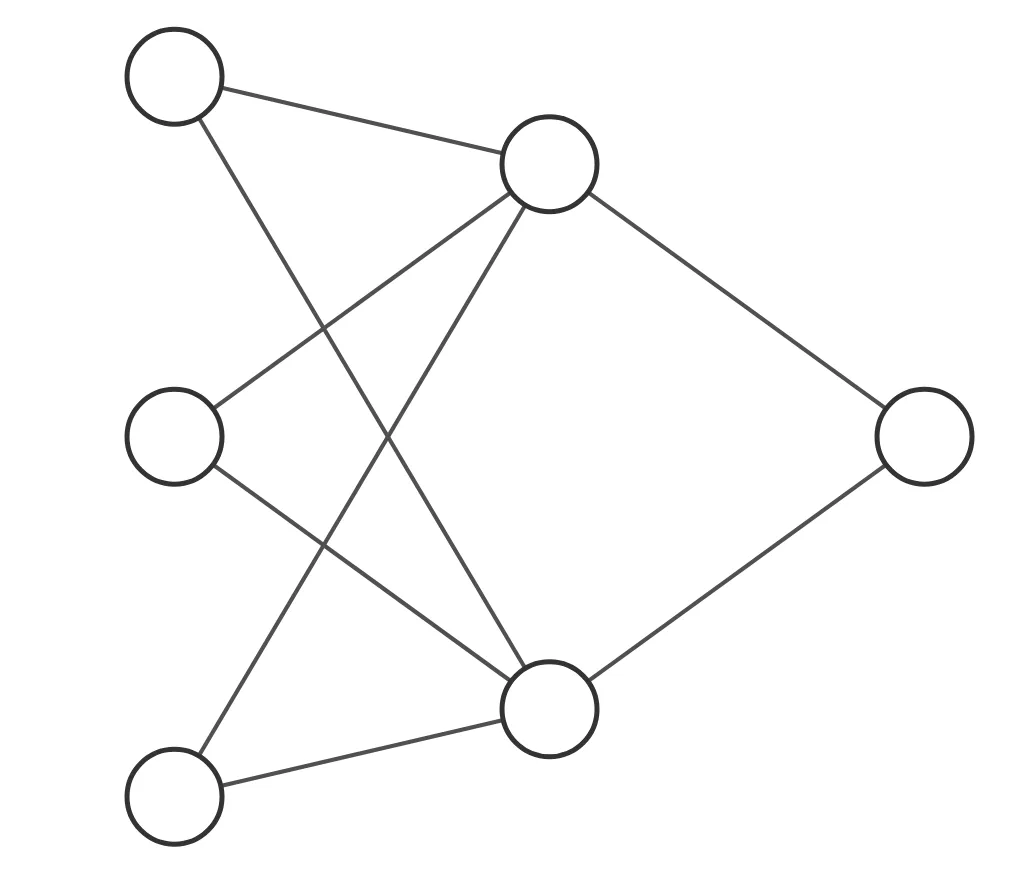
当然,你现在不需要知道模型是怎么构建得到的。在这个模型中,最左侧有三个圆圈,也被称为神经元,这是模型的输入层,三个神经元会分别对应这个问题的三个特征变量“温度,湿度,风向”,在这几个特征的值被输入到模型之后,模型内部会进行运算,最右侧是一个神经元,它输出的就是模型运算的结果即“是否降雨”的值。所以不难看出,模型是根据问题来进行“客制化”定制的,模型的输入层神经元个数要和问题的所给出数据的特征个数相同,输出神经元个数也要和问题所研究的label个数相同,几乎不存在某个MLP模型能完美解决多个或者所有问题。至此我们大致了解了模型的训练数据、如何根据问题构建模型、模型运行的大致过程。
MLP神经网络学习时的运行过程
在上一个文段我们已经了解了MLP神经网络在执行预测时的过程,接下来将讲解MLP神经网络的学习过程和学习原理
在中学阶段我们基本上都会接触过一个词叫“拟合”,例如通过散点图得出一条能大致描述这些散点的一次函数方程,这是一个很简单的线性拟合,可以通过最小二乘法实现。对于非线性的关系,如下图,假设我知道了ABCDE点的坐标也就是XY对,那么而可以通过使用二次函数去拟合这个非线性关系,这时候所得出的二次函数表达式就是这个非线性关系的模型,这时如果要进行预测任务,例如我得到了一个新的点F的x坐标,此时我就可以预测F的y值,即使它可能并不符合真实情况,因为真实情况下的非线性关系可能不是这个二次函数拟合出的模型。讲这些只是为了介绍“拟合”这个词以及拟合数据后的模型能进行预测这个事。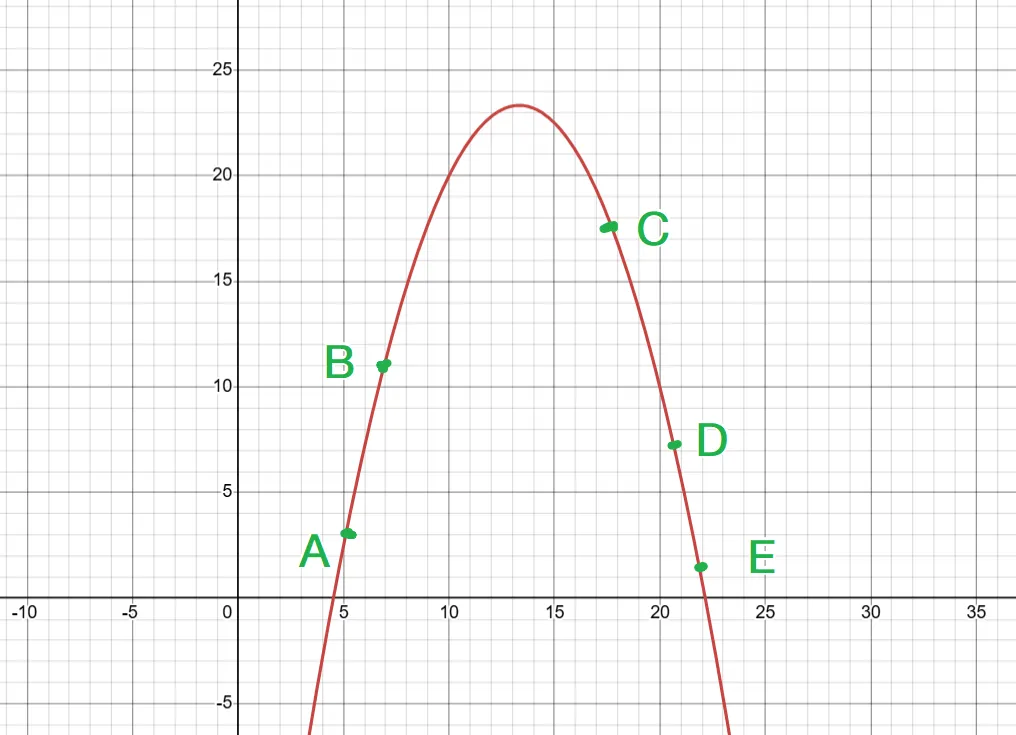
在MLP神经网络中,模型对数据的拟合过程与人类学习存在显著相似性,因此人们更倾向于使用 “学习” 这一术语。为便于理解,我们可以通过类比人类应试教育场景,来阐释 MLP 神经网络的学习机制。
在传统应试教育中,学生们有着共同的目标 —— 获取更高分数。现在,我们构建一个 “理想环境”:在此环境下,没有课本和课堂教学,学生仅能通过反复考试进行学习。每次考试结束后,学生可以得知每道题的正误。经过 N 次模拟考试后,将迎来最终考核,所有学生的目标都是在最终考核中取得高分。在这个场景下,学生初次考试时往往只能随机作答;随着考试次数增加,他们会经历 “初次考试→随机作答→知晓答案正误→复盘错题→掌握答题技巧→下一次考试→有策略地答题” 的循环过程。当模拟考试次数足够多时,部分学生就有可能在最终考核中获得满分。
这一过程与 MLP 神经网络的学习过程存在诸多相似之处:
- 学习目标:如同学生在应试教育中追求高分,MLP 神经网络的学习目标是让模型预测值尽可能接近实际值,即最小化预测误差。
- “考试” 机制:MLP 神经网络通过 “计算损失值” 来衡量预测效果。损失值量化了模型预测值与实际值之间的差异,它并非简单的数值相减,而是通过特定的损失函数(如均方误差、交叉熵损失等)进行计算。
- 初始状态:在训练初期,MLP 神经网络的权重参数会随机初始化,类似于学生初次考试时的随机作答。
- 学习过程:
- 前向传播:对应学生在考试中答题的过程,模型基于当前权重参数对输入数据进行计算,生成预测结果。
- 计算损失值:如同考试评分,模型根据预测值与实际值的差异计算损失,用以评估本次预测的表现。
- 反向传播:类比学生复盘考试过程,模型通过反向传播算法,将损失值从输出层反向传递至输入层,计算各层参数的梯度。
- 梯度下降:类似于学生掌握答题技巧,模型根据计算得到的梯度,对权重参数进行更新,以降低损失值,优化预测效果。
MLP 神经网络的学习过程,正是通过 **“前向传播(考试答题)-->计算损失值(考试得分)-->反向传播(复盘考试)-->梯度下降(掌握答题技巧)”**这一流程的不断迭代,逐步调整模型参数,提升预测准确性。
MLP神经网络学习原理解析
上一节我们通过类比的方式来了解了MLP模型学习的大致过程,现在我们将从神经网络的组成来解析“神经网络为什么能学习”
我们依然以前面提到的分类问题为例,针对这个问题我们设计了如图的一个MLP神经网络模型,有两层神经元(第一层作为输入层不算是神经元)
分类问题:“根据温度、温度、风向预测是否降雨” 特征:“温度,温度,风向” label:“是否降雨”
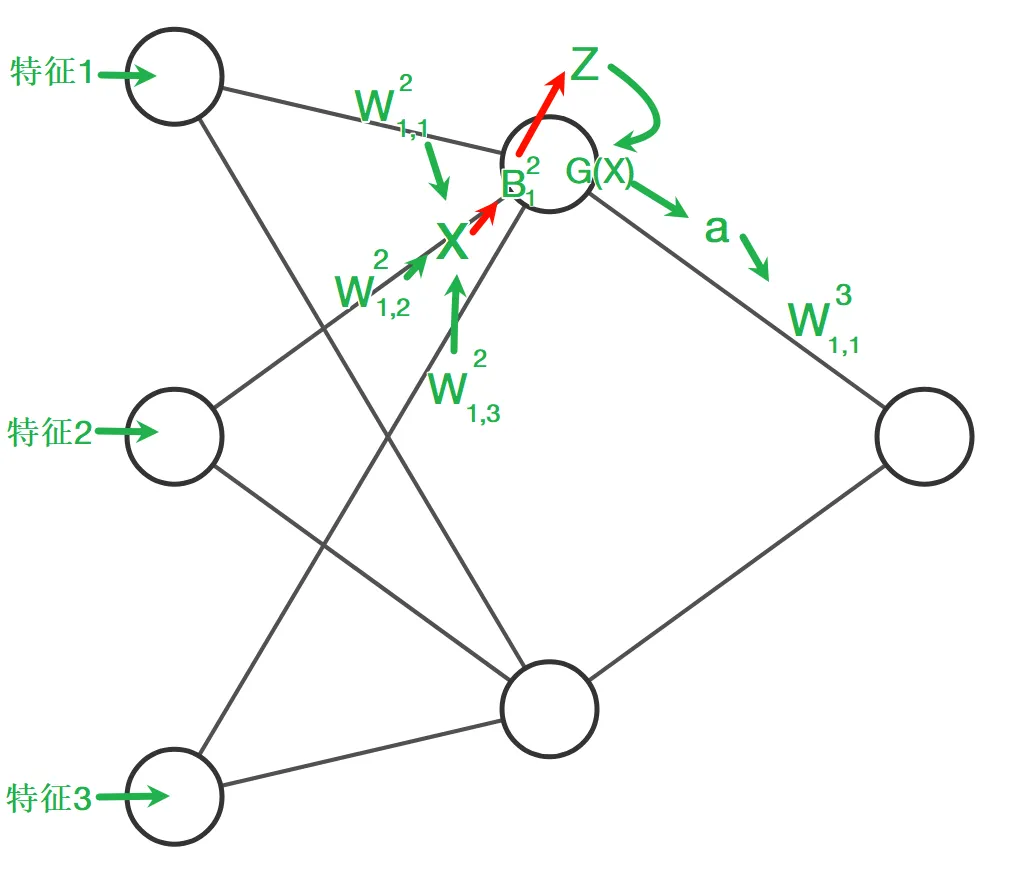
- 激活函数:在模型内引入非线性因素,拟合数据的非线性关系,激活函数就是一个确定的函数表达式,只对权重和偏置处理过后的数据进行激活
- 权重:模型对特征的权重是模型在学习过程中认为这个特征对输出内容的影响程度,有时一个特征的权重较大,可能是因为它与其他特征存在某种组合关系,共同对模型输出产生重要影响。
- 偏置:用于防止加权求和后的内容为0导致不能被激活,所以设置一个偏执
- 前向传播:输入的训练数据经过多层神经元从前往后计算得到预测值的过程
- 损失函数:描述预测值和真实值差距的函数,损失函数有多种,需要根据模型的任务和特征来选择相应损失函数,损失函数得出的值一定大于等于0
- 反向传播:通过损失函数对各层神经元之间的权重和偏置求偏导,得出损失函数对各个权重和偏置的偏导
- 梯度更新:为了使得损失函数接近于0,结合学习率对权重和偏置的梯度更新
未完待续......